
馬 柯1,賈為征2,劉國峰2,韓立鵬2
(北京首鋼自動化信息技術有限公司京唐運行事業部,河北 唐山 063200)
摘要:收集了冷軋產線立式加熱爐帶鋼溫度控制下的數據集,該數據集包含有帶鋼溫度、厚度、寬度、運行速度、帶鋼長度、功率。通過python語言搭建機器學習模型,對數據集進行學習、建模,通過影響因素來預判帶鋼實際溫度,并通過均方根誤差來判定模型的精度。
關鍵詞: 帶鋼溫度;均方根誤差;機器學習;LightGBM算法
0 引言
退火爐加熱模型計算中,對于帶鋼進入爐區溫度的預判及其重要,精度高的預判能夠提供一個更精準的加熱策略,來滿足生產工藝需求,從而減少熱瓢曲現象的發生[1]。目前產線應用較多的加熱模型,依靠實時的測量值和帶鋼的物性實時地計算/預測帶鋼在各段出口的溫度,使用了基于物理熱交換(對流換熱,輻射換熱)的數學模型。本文針對鍍鋅產線立式加熱爐,我們收集了大量數據集[2],采用python及其機器學習生態系統,對數據集分析,建模,來完成帶鋼在加熱區域出口溫度實際值的預判[3]。通過均方根誤差計算,來驗證模型的好壞。
1 數據集
數據集為鍍鋅產線立式加熱爐,輻射管加熱段,利用帶鋼溫度控制模式下數據,產線運行速度不為0。帶鋼厚度在0.5~1.5 mm之間,帶鋼速度為1~130 m/min的爐區加熱數據,另外包含帶鋼長度、帶鋼溫度、功率實際值。數據集是13 249×9的一個二維數組,部分數據見表1。表中:number為序列號,Thick為帶鋼厚度,Width為寬度,Length為長度,Spd_mea速度測量值,ST_mea加熱段出口處帶鋼溫度測量值, PoAvg_mea加熱段平均功率值,TTsAvg_mea加熱段區域溫度測量值,ST_est熱模型計算出的加熱段出口段溫度,ST加熱段入口處帶鋼溫度測量值。
表1 數據集示例
|
number |
Thick/ mm |
Width/mm |
Length/mm |
Spd_mea/(m·min-1) |
ST_mea/℃ |
TTsAvg_mea/℃ |
PoAvg_mea/% |
ST_est/℃ |
ST/℃ |
|
1 |
0.575 |
1224 |
3549 |
130 |
790 |
839 |
63 |
794 |
190 |
|
2 |
0.575 |
1224 |
3539 |
130 |
790 |
839 |
63 |
794 |
190 |
|
3 |
0.575 |
1224 |
3527 |
130 |
790 |
839 |
63 |
794 |
189 |
|
4 |
0.575 |
1224 |
3516 |
130 |
790 |
839 |
63 |
794 |
190 |
|
5 |
0.575 |
1224 |
3516 |
130 |
790 |
839 |
63 |
794 |
189 |
2 目標和評估指標
目標是利用測試集中可用的信息,來預測帶鋼經過輻射管加熱段后的實際溫度。評估指標為,利用均方根誤差(root mean squared error, RMSE)來評價模型的好壞[4]。其數學公式為

當均方根誤差越小時,表示數據的擬合效果越好,測試值越接近實際值。
3 分析數據
為了對數據集每一個字段進行觀察,采用繪制箱式圖的方式來得到數據字段的分布。采用Python語言,利用數據可視化相關庫完成,導入matplotlib、seaborn、numpy、pandas,進行繪制,輸出結果如圖1所示。通過圖1能夠直觀了解到每個字段的分布情況。
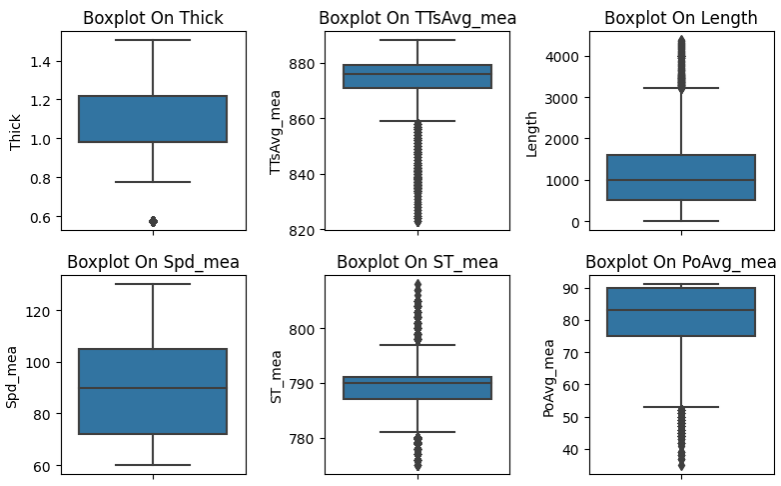
圖1 特征值箱式圖
繪制各個數值特征之間的相關矩陣熱圖[5],來理解目標變量如何受數值特征影響,繪制 ST_mea 與 ["Thick", "Width", "Length", "Spd_mea", "PoAvg_mea", "TTsAvg_mea","ST","ST_est","ST_mea"]之間的相關矩陣熱圖,如圖2所示。通過特征值之間相關矩陣熱圖,能夠得到特征值對帶鋼溫度影響程度,影響程度從大到小依次為PoAvg_mea、Spd_mea、ST、 TTsAvg_mea、Thick、Length、Width。另外,Spd_mea和Thick、Length、Width有很強的相關性[6],ST_est為加熱模型計算出的實際溫度,不用于建模,可用于對比擬合精度。
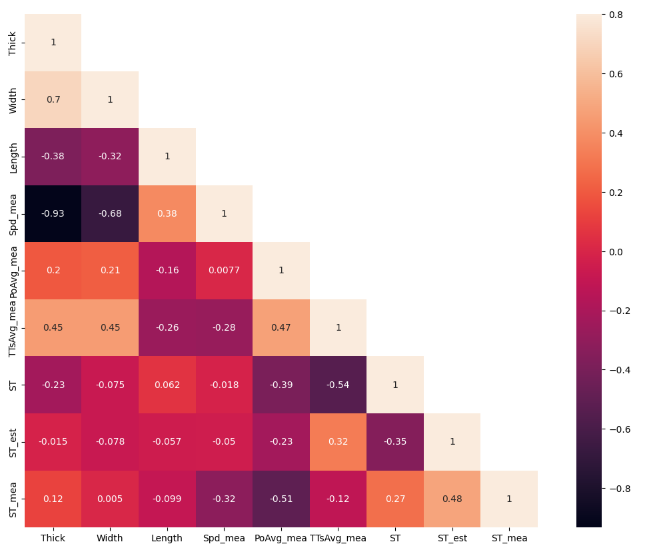
圖2 特征值相關矩陣熱圖
4 模型的建立與求解
首先,準備好數據,訓練集數據為data_train,X_train包含了PoAvg_mea、Spd_mea、ST、 TTsAvg_mea、Thick、Length、Width這幾個特征,Y_train為ST_mea。測試集數據為data_test, X_test包含了測試集數據PoAvg_mea、Spd_mea、ST、 TTsAvg_mea、Thick、Length、Width,y_test為測試集數據ST_mea。部分代碼如下:

定義評價函數,實現均方根誤差的計算,引用Numpy庫,pandas庫、 calendar庫完成計算,部分代碼如下:

為了訓練出高精度的模型,引入LightGBM算法,LightGBM是微軟開發的boosting集成模型,LightGBM作為常見的強大Python機器學習工具庫,具有以下優點:更快的訓練效率,低內存使用,更高的準確率,支持并行化學習,可處理大規模數據,支持直接使用 category 特征。面對工業級海量的數據,普通的 GBDT 算法無法滿足需求。 LightGBM解決能夠解決大數據量級下的 GBDT 訓練問題,以便工業實踐中能支撐大數據量并保證效率[7]。
引入機器學習lightgbm庫,對數據集進行擬合訓練,利用訓練結果進行測試集計算,將結果利用均方根計算誤差[8],代碼如下:

通過對數據集X_train, y_train經過LightGBM模型的訓練,得到的計算模型去求解X_test值[9],最終得到y_pred就是通過模型計算出的測試集帶鋼在出口時的實際溫度。通過均方根誤差計算,誤差為0.007787,同樣我們對熱模型求出的溫度實際值和溫度測量值進行均方根誤差計算,得到的結果時0.013 096。輸出結果見表2。
表2 誤差統計表
|
模型 |
RMSLE |
|
hot-mod |
0.013 096 |
|
LightGBM |
0.007 787 |
5 結語
利用Python機器學習進行建模得到的結果,精度在這種情況下大于熱模型的計算結果。在進行爐子建模過程中,可以將機器學習模型納入計算過程中,結合熱模型,以及PID算法,能夠實時對模型計算結果進行調節,以達到理想的精度[10]。
參考文獻
[1] 路佳佳.基于集成特征選擇和隨機森林的古代玻璃分類模型[J/OL].硅酸鹽學報:1-6[2023-03-15].https://doi.org/10.14062/j.issn.0454-5648.20220790.
[2] 劉玉敏,趙哲耘.基于特征選擇與SVM的質量異常模式識別[J/OL].統計與決策,2018(10):47-51[2023-03-15].https://doi.org/10.13546/j.cnki.tjyjc.2018.10.010.
[3] 徐小青,郝曉東,周石光,等.熱鍍鋅退火過程中的溫度控制策略[J].鋼鐵研究學報,2016,28(1):44.
[4]楊枕,任偉超,李洋龍,等.連續退火爐二級管溫模型優化[J].冶金自動化,2018,42(4):40.
[5] 揣雪雨. 基于LightGBM算法的個人信用評估模型研究[D]. 鄭州:鄭州大學,2020.
[6]郭英,陳壘.連續退火爐帶鋼溫度數學模型開發及應用[J].冶金能源,2021,40(06):28.
[7] 邢長征,徐佳玉.LightGBM混合模型在乳腺癌診斷中的應用[J/OL].計算機工程與應用:1-10[2023-03-15].
[8] 張笑宇,沈超,藺琛皓等.面向機器學習模型安全的測試與修復[J/OL].電子學報,2022(12):2884
[9] 周書蔚,楊冰,王超等.機器學習法預測不同應力比6005A-T6鋁合金疲勞裂紋擴展速率[J/OL].中國有色金屬學報:1-17[2023-03-15].
[10] 李贊. 異構數據集下通信高效的聯邦學習算法研究[D].合肥:中國科學技術大學,2022.