
張海剛1,2) ,張森1,2) ,尹怡欣1,2)
1) 北京科技大學(xué)自動化學(xué)院,北京100083 2) 北京科技大學(xué)鋼鐵流程先進(jìn)控制教育部重點(diǎn)實驗室,北京100083
摘 要 針對高爐故障診斷系統(tǒng)快速性和準(zhǔn)確性的要求,提出基于全局優(yōu)化最小二乘支持向量機(jī)的策略. 首先,采用變尺度離散粒子群對最小二乘支持向量機(jī)的參數(shù)和故障特征的選取進(jìn)行優(yōu)化; 然后,利用核主元分析法對選取的特征向量進(jìn)行壓縮整理; 最后,構(gòu)造了以Fisher 線性判別率為標(biāo)準(zhǔn)的啟發(fā)式糾錯輸出編碼. 仿真結(jié)果表明,通過對故障訓(xùn)練樣本有意義地分割重組,用較少的最小二乘支持向量機(jī)分類器,得到較高的故障判斷準(zhǔn)確率且增強(qiáng)了整個系統(tǒng)的實時性.
關(guān) 鍵 詞 高爐; 故障診斷; 最小二乘分析; 支持向量機(jī); 全局優(yōu)化
鋼鐵工業(yè)是我國國民經(jīng)濟(jì)的基礎(chǔ)產(chǎn)業(yè)和支柱產(chǎn)業(yè)[1]. 高爐煉鐵在鋼鐵工業(yè)中處于舉足輕重的地位.高爐煉鐵系統(tǒng)生產(chǎn)設(shè)備繁多,具有多耦合、大延時、非線性等特點(diǎn). 盡管在高爐本體上安裝了很多自動化的檢測裝置,然而由于高爐運(yùn)行爐況復(fù)雜,無法建立準(zhǔn)確的機(jī)理模型,在高爐自動控制決策過程中,仍將其當(dāng)為“黑箱”系統(tǒng)進(jìn)行處理. 高爐生產(chǎn)追求穩(wěn)定,穩(wěn)定爐況不僅能夠保證鐵水質(zhì)量,而且能夠提高煤氣利用率,達(dá)到節(jié)能減排的目的. 高爐爐況故障診斷在高爐自動化控制的研究中一直是熱點(diǎn)話題,準(zhǔn)確及時的故障診斷技術(shù)能夠確定高爐的穩(wěn)定生產(chǎn),降低故障所帶來的經(jīng)濟(jì)損失[2].
在高爐生產(chǎn)中,由于缺少準(zhǔn)確的機(jī)理模型,往往從數(shù)據(jù)驅(qū)動角度建立高爐故障診斷模型[3]. 基于專家系統(tǒng)的故障診斷方法,計算機(jī)模仿專家經(jīng)驗,進(jìn)行故障決策[4]. 雖然引進(jìn)國外的專家系統(tǒng)有一定的效果,但是其價格昂貴,并且國內(nèi)大多數(shù)高爐檢測設(shè)備落后,操作管理水平低,造成重要參數(shù)的數(shù)據(jù)不完整,不準(zhǔn)確,導(dǎo)致國外專家系統(tǒng)難以適合我國國情. 文獻(xiàn)[5]基于人工神經(jīng)網(wǎng)絡(luò)建立了高爐故障診斷模型,取得了不錯的效果. 但由于其建立在大數(shù)定理的漸近理論之上,要求學(xué)習(xí)樣本足夠多,收斂速度比較慢且容易陷入局部極值或過學(xué)習(xí)的困境,在實際應(yīng)用中隱含層的層數(shù)及每層神經(jīng)元數(shù)目如何確定也無規(guī)律可循. 李振[6]將貝葉斯技術(shù)運(yùn)用到高爐故障診斷中,設(shè)計了因果關(guān)系貝葉斯網(wǎng)絡(luò)診斷模型. 然而高爐的智能故障診斷面臨的是典型故障樣本少、特征參數(shù)呈非線性耦合且維數(shù)較高的模式識別難題,所建立的貝葉斯模型往往達(dá)不到期望的精度. 除此之外,高爐處于復(fù)雜的工業(yè)生產(chǎn)環(huán)境中,樣本數(shù)據(jù)往往受到噪聲干擾,這要求故障診斷算法有很強(qiáng)的魯棒性. 高爐故障具有不同的形式,屬于多分類問題,設(shè)計合理有效的故障檢測分類器至關(guān)重要. 同時高爐生產(chǎn)對于故障檢測的及時性也有一定的要求[5],及時準(zhǔn)確的進(jìn)行故障檢測報警,不僅能夠減少損失,而且能夠保證高爐順行,延長高爐壽命.
本文針對冶煉過程中出現(xiàn)的懸料、崩料和管道行程三種典型故障,提出基于全局優(yōu)化支持向量機(jī)的多類別高爐故障診斷方法. 一方面,在智能故障診斷系統(tǒng)的構(gòu)建過程中,為了降低特征空間的維數(shù),減少存儲空間的占用,提高機(jī)器學(xué)習(xí)的效率,需要對高爐的故障特征參數(shù)進(jìn)行自動的篩選. 在數(shù)據(jù)預(yù)處理階段,我們采用核主成分分析( kernel principal component analysis,KPCA) 方法對高爐故障特征數(shù)據(jù)進(jìn)行降維處理,保留和高爐故障關(guān)聯(lián)性較高的特征數(shù)據(jù),提高檢測準(zhǔn)確率. 另外核函數(shù)的參數(shù)選擇和支持向量機(jī)的懲罰因子影響著故障診斷系統(tǒng)的訓(xùn)練效果,為了避免人為設(shè)定參數(shù)的弊端,需要系統(tǒng)自發(fā)地對參數(shù)的最優(yōu)值進(jìn)行尋找. 本文在粒子群算法[7]的基礎(chǔ)上,提出變尺度離散粒子群參數(shù)優(yōu)化方法,通過加強(qiáng)最優(yōu)粒子的影響力,增強(qiáng)了系統(tǒng)的穩(wěn)定性. 另一方面,高爐故障診斷本質(zhì)上是多類別分類問題,而支持向量機(jī)是針對二元分類問題的學(xué)習(xí)方法,通常的處理方式是將復(fù)雜的多元分類問題分解為多個簡單的二元分類問題. 糾錯輸出編碼是一種分解重組多元分類問題的通用方法,其中一對多、密集隨機(jī)編碼法與一對一、稀疏隨機(jī)編碼法分別是經(jīng)典的二元和三元編碼方法的實例[7]. 然而,以上方法的編碼矩陣是預(yù)先定義好的,在編碼矩陣的創(chuàng)建過程中,沒有考慮到訓(xùn)練樣本的數(shù)據(jù)特征,使得訓(xùn)練過程具有一定的盲目性. 本文采用以Fisher 線性判別率為標(biāo)準(zhǔn)的啟發(fā)式糾錯輸出編碼,該方法具有兩個方面的優(yōu)勢: 首先,啟發(fā)式的編碼過程允許類集合按照最大的判別率重新組織,從而使編碼矩陣的拓?fù)浣Y(jié)構(gòu)同一對一和一對多方法固定的方式相比變得更加靈活. 其次,與隨機(jī)策略需要大量的分類器相比,有意義的重組顯著減少了分類器的數(shù)量,從而得到較好的性能且提高了訓(xùn)練的速度.
我們首先詳細(xì)介紹本文提出的全局優(yōu)化最小二乘支持向量機(jī)分類算法,其次我們建立高爐智能故障診斷模型,最后展示基于真實生產(chǎn)數(shù)據(jù)的故障仿真結(jié)果.
1 基于全局優(yōu)化最小二乘支持向量機(jī)的多類別分類方法
1. 1 最小二乘支持向量機(jī)
支持向量機(jī)( SVM) 能較好地解決小樣本、非線性以及高維數(shù)的模式識別問題. 支持向量機(jī)通過結(jié)構(gòu)風(fēng)險最小化原理來提高泛化能力,可以用于解決二元分類問題,已在模式識別、信號處理和函數(shù)逼近領(lǐng)域得到應(yīng)用[8--9]. 最小二乘支持向量機(jī)( least-squares supportvector machine,LS-SVM) 是Suykens 和Vandewalle[8]在Vapnik 的標(biāo)準(zhǔn)支持向量機(jī)的基礎(chǔ)上提出的一種改進(jìn)方法. 最小二乘支持向量機(jī)在優(yōu)化問題中引入誤差的平方項,用等式約束取代原先支持向量機(jī)的不等式約束條件,將耗時的二次規(guī)劃問題轉(zhuǎn)化為線性方程組的求解,大幅度地簡化了訓(xùn)練過程.
給定具有N 個n 維樣本向量的訓(xùn)練集T = { ( x1,y1) ,( x2,y2) ,…,( xN,yN) } ,其中xk∈Rn 是第k 個輸入向量,yk∈Y = { 1,- 1} 是第k 個輸入向量在二元分類問題中的類標(biāo)簽. 當(dāng)樣本在輸入空間不能被線性分開時,選擇一個非線性映射Φ(·) : Rn→H,把樣本向量從輸入空間Rn 映射到特征空間H. 當(dāng)在特征空間H 構(gòu)建最優(yōu)超平面時,訓(xùn)練算法只需要計算該空間向量間的內(nèi)積,即Φ( xi) Φ( xj) ,通過引入核函數(shù)κ( xi,xj) = Φ( xi) Φ( xj) ,使得高維空間的內(nèi)積運(yùn)算轉(zhuǎn)化為原始輸入空間核函數(shù)的計算. 支持向量分類機(jī)的目標(biāo)是在特征空間中構(gòu)建最優(yōu)線性決策函數(shù):
![]()
其中,Φ(·) 是從輸入向量到高維特征空間的非線性映射,ω 是最優(yōu)分類超平面的法向量,b 為偏移量.
假設(shè)訓(xùn)練集在特征空間中是線性可分的,最優(yōu)分類超平面應(yīng)滿足如下條件:
![]()
當(dāng)訓(xùn)練集在特征空間中為線性不可分時,任何分類超平面都必然有錯誤的劃分,因此不能要求所有訓(xùn)練點(diǎn)均滿足約束條件( 2) . 為此,對第個訓(xùn)練點(diǎn)( xk,yk) 引入松弛變量ξk≥0,把約束條件放寬為:
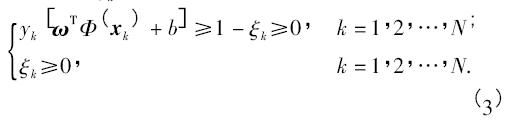
ξ = ( ξ1,ξ2,…,ξN) 體現(xiàn)了訓(xùn)練集被錯分的情況,而由ξ可以構(gòu)造出表述訓(xùn)練集被錯劃的程度. 根據(jù)結(jié)構(gòu)風(fēng)險最小化原則,最小二乘支持向量機(jī)在目標(biāo)函數(shù)中選取ξ2 作為損失函數(shù),尋找最優(yōu)超平面的問題轉(zhuǎn)化為下列二次規(guī)劃問題
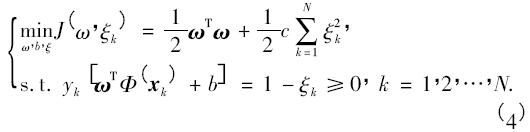
其中,c 是為了均衡目標(biāo)函數(shù)所引進(jìn)的懲罰系數(shù). 求解式( 4) ,需引入Lagrangian 函數(shù)L( ω,b,ξ; αk) 即
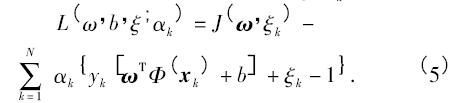
其中αk為Lagrangian 乘子. 根據(jù)Karush--Kuhn--Tucker( KKT) 優(yōu)化條件[10]可得
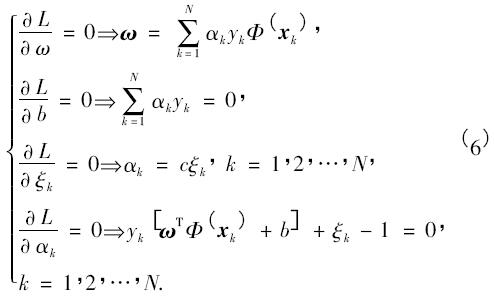
引入某個核函數(shù)κ(·) 后,最優(yōu)化問題最終轉(zhuǎn)化成式( 7) 線性方程組的求解
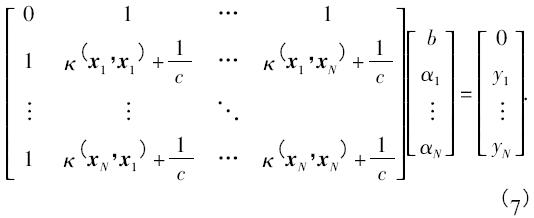
解方程組得到最優(yōu)解α* = ( α*1,α*2,…,α*N) 和b* 得到?jīng)Q策函數(shù)
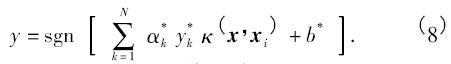
1. 2 Fisher 線性判別糾錯輸出編碼
高爐故障形式多樣,不同故障有不同的表現(xiàn)形式.在本文中,我們考慮三種高爐典型故障形式: 懸料、崩料和管道行程,是一種多分類問題. 在實際的應(yīng)用過程中,支持向量機(jī)被證明是強(qiáng)有力的二元分類方法[11]. 然而,當(dāng)需要處理多元分類問題時,支持向量機(jī)不能直接用來處理這種信息. 在支持向量機(jī)算法處理多分類問題中,往往將多元分類問題轉(zhuǎn)化為一對多的二元分類問題. 然而這種轉(zhuǎn)化往往會增加分類器的個數(shù),增加訓(xùn)練時間. 在這一小節(jié)中,我們介紹Fisher線性判別糾錯輸出編碼,并將其應(yīng)用到高爐的多故障識別算法中.
1. 2. 1 糾錯輸出編碼
糾錯輸出編碼( error correcting output codes,ECOC) 是處理多元分類問題的通用框架,它能夠通過編碼減少數(shù)據(jù)樣本維數(shù),提高樣本質(zhì)量,從而可以保證采用較少的支持向量機(jī)分類器建立故障診斷模型,解決支持向量機(jī)多元分類問題[12]. 總體來講,可以把糾錯輸出編碼方法分解為兩個不同的階段: 編碼和解碼.在編碼階段,對于一組給定類別的訓(xùn)練樣本集合,為每個類別設(shè)計一套單獨(dú)的碼字( 代表每個類的編碼的比特序列) ,碼字的每個位置標(biāo)示了某一類的訓(xùn)練樣本在相應(yīng)的二元分類器中的標(biāo)簽歸屬. 在解碼階段,尋找與實驗樣本分類結(jié)果最匹配的碼字,指定輸入向量的類別標(biāo)簽,從而得到最終的分類決策. 通過拆分重組原始的類別集合并且將二元分類方法嵌入以實際問題為導(dǎo)向的糾錯編碼設(shè)計過程,有效的解決了復(fù)雜的多分類問題.
在編碼步驟中,對于給定的待學(xué)習(xí)的N 類樣本集合,在為每個類分配一行獨(dú)一無二的長度為n 的碼字時,形成了n 個不同的二元分類問題. 碼字的每個比特位根據(jù)某類訓(xùn)練樣本集在相應(yīng)二元分類器的歸屬,被編碼為+ 1( 正例) 或者- 1( 負(fù)例) . 將碼字按照矩陣的行向量排列起來,可以得到一個二元的N × n 編碼矩陣M,其中Mij∈{ - 1,+ 1} . 在此基礎(chǔ)上,Allwein等[13]在編碼過程中引入了0 符號,這意味著在某些分類器中某些類的樣本是不被考慮的,通過忽略這些類的樣本對分類器的影響,三元的糾錯輸出編碼結(jié)構(gòu)豐富了類別劃分的多樣性,最后得到三元編碼矩陣M,其中Mij∈{ - 1,0,+ 1} .
在解碼步驟中,應(yīng)用n 個二元分類器,可以得到每個測試樣本長度為n 的輸出編碼,根據(jù)輸出編碼與各個碼字之間的距離測度可以決定其類別的歸屬. 常用的距離測度是漢明距離,對于任意的測試樣本的分類結(jié)果可以用如下公式表示
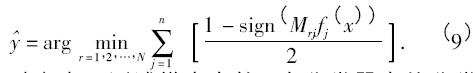
其中,f j( x) 表示測試樣本在第j 個分類器中的分類結(jié)果[14].
為了尋找碼字長度簡短并具有高分辨力的編碼矩陣,總體的算法描述如下:
第一步,創(chuàng)建列向量編碼二叉樹,利用以Fisher 線性判別率為標(biāo)準(zhǔn)的浮動搜索法,遞歸地尋找第k 個父節(jié)點(diǎn)的類集合Sk中具有最大判別率的兩個分區(qū){ φ1k,φ2k} .
第二步,根據(jù)得到的分割結(jié)果{ φ1k,φ2k} 為編碼矩陣M 的第k 列賦值.
其中,第一步創(chuàng)建了列向量編碼二叉樹. 表1 描述了創(chuàng)建列向量編碼二叉樹的算法. 每一個樹節(jié)點(diǎn)定義了一個類集合分割的問題,每個節(jié)點(diǎn)的分割必須滿足使判別率最大化的條件. 通過最大化數(shù)據(jù)x 和為分割結(jié)果所創(chuàng)建的類標(biāo)簽d 之間的交互信息可以得到最終的列代碼. 算法中d 是一個離散的隨機(jī)變量,因此給定類集合Sk的一個分割結(jié)果{ φ1k,φ2k} = BP( Sk) ,d按如下形式定義:
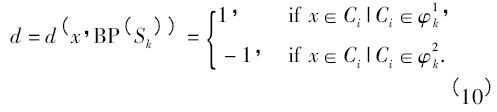

將二叉樹視為尋找碼字的手段,第二步是填充糾錯輸出編碼矩陣的過程. 利用除了葉節(jié)點(diǎn)外的每個根節(jié)點(diǎn)得到的列代碼,組成了編碼矩陣M. 列代碼作為矩陣M 的列向量依次排列. 為了創(chuàng)建每一個列代碼,可以使用父節(jié)點(diǎn)和子節(jié)點(diǎn)的關(guān)系進(jìn)行描述. 對于給定的類Cr和節(jié)點(diǎn)k 的類集合k: { φ1k∪φ2k} ,其中φ1k和φ2k分別是節(jié)點(diǎn)k 的子節(jié)點(diǎn),矩陣M 按如下方式填充:
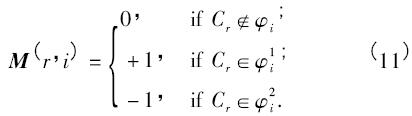
注意到列的數(shù)量n 和內(nèi)部節(jié)點(diǎn)的數(shù)量一致. 容易得出,在任何的二叉樹中,如果葉節(jié)點(diǎn)的數(shù)量是Nc,內(nèi)部節(jié)點(diǎn)的數(shù)量是Nc - 1,因此可以確定碼字的長度是Nc - 1.
圖 1 展示了一個八元分類問題列向量編碼二叉樹構(gòu)造的過程.
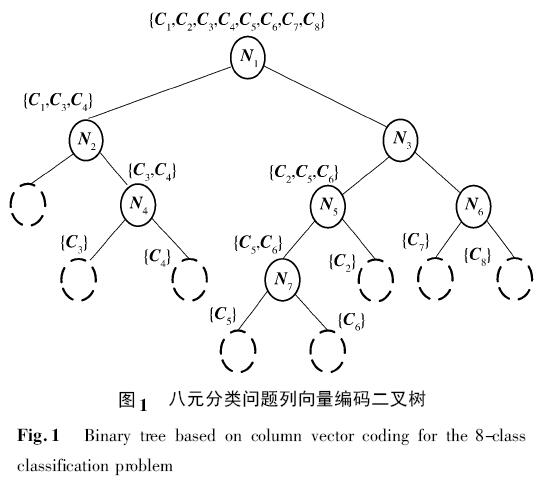
圖2 顯示了判別糾錯輸出編碼矩陣的結(jié)果. 其中白色的方格表示相應(yīng)的位置被編碼為+ 1,黑色的方格表示- 1,灰色的方格表示0. 因此,C6類的碼字是{ 1,0,- 1,0- 1,0,1} . 編碼矩陣的第i 列定義了一個二元分類問題,將相應(yīng)的二元分類器hi進(jìn)行訓(xùn)練. 例如,分類器h5區(qū)分{ C5,C6} 和{ C2} .

1. 2. 2 Fisher 線性判別浮動搜索法
在本小節(jié),我們設(shè)計了一種Fisher 線性判別率為標(biāo)準(zhǔn)的啟發(fā)式糾錯輸出編碼,并將其運(yùn)用到判別糾錯輸出編碼算法中. 該算法能夠利用較少的支持向量機(jī)分類器,實現(xiàn)高爐故障的多分類問題.
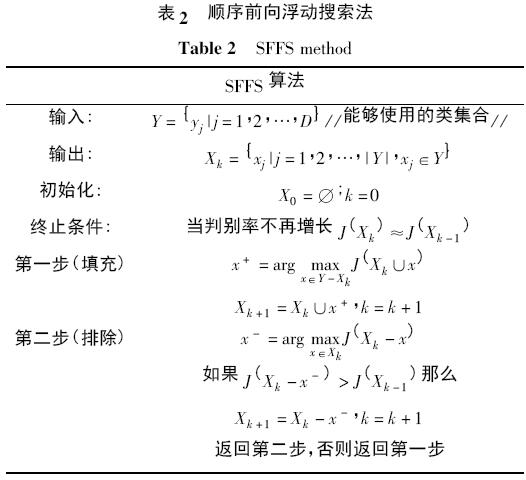
回顧表1 中描述的算法,為了將類集合分割成兩個部分,需要一個最大化判別率的過程. 但是,最好的分割子集需要在所有可能的分割中無遺漏的尋找,由于這種方法是不切實際的,所以必須使用一種次優(yōu)的策略. 浮動搜索方法是一種次優(yōu)的順序搜索方法,能夠緩解窮舉搜索法在進(jìn)行分割選擇時,產(chǎn)生的高額計算代價. 而且,這種方法允許搜索方向是變化的,從而解決了許多順序搜索方法的主要限制.
表2 中的方法為順序前向浮動搜索法( sequentialfloating forward selection,SFFS) . 這種方法以空的類集合X0開始并在新集合的判別率增加時被逐漸填充.在填充階段,對于類集合Xk最有意義的類被納入進(jìn)來. 在條件排除步驟,如果判別率繼續(xù)增長則最差的類被移除.
為了避免高維空間龐大的計算量,選擇Fisher 線性判別率作為分割類集合的標(biāo)準(zhǔn). 假設(shè)C1和C2是二分類問題的兩個類. 定義Fisher 線性判別率為
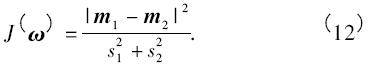
式中m1和m2是樣本的均值,s1和s2是C1和C2各自的方差. 定義類內(nèi)散射矩陣Sω和類間散射矩陣Sb為:
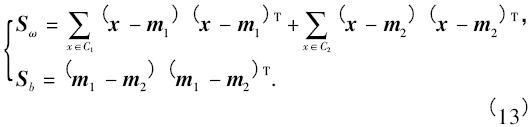
根據(jù)上面的結(jié)果,J( ω) 可以被寫成
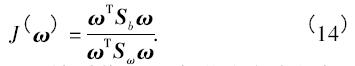
類間散射矩陣Sω可以被看作是一個類的密度指標(biāo).并且,類間散射矩陣Sb可以被看作是一個類的位置指標(biāo). 因此,可以定義判別率

1. 3 變尺度離散粒子群
高爐生產(chǎn)環(huán)境復(fù)雜,生產(chǎn)數(shù)據(jù)往往遭到工業(yè)噪聲的干擾,這對于故障識別算法有強(qiáng)魯棒性的要求. 另外,高爐運(yùn)行狀態(tài)繁多,各種爐況之間相互轉(zhuǎn)化,設(shè)計穩(wěn)定可靠的故障分類器至關(guān)重要. 最小二乘支持向量機(jī)分類算法中學(xué)習(xí)參數(shù)的選擇,對于故障分類精度影響嚴(yán)重. 合適的學(xué)習(xí)參數(shù)不僅能夠提高分類器的故障識別精度,而且能夠保證分類器穩(wěn)定運(yùn)行,滿足高爐生產(chǎn)的需求. 在此我們采用粒子群算法( particle swarmoptimization,PSO) 對于最小二乘支持向量機(jī)分類器的學(xué)習(xí)參數(shù)進(jìn)行優(yōu)化. 粒子群算法起源于對鳥群尋找食物行為的模仿[15]. 標(biāo)準(zhǔn)粒子群優(yōu)化算法主要針對連續(xù)參數(shù)進(jìn)行搜索運(yùn)算,但高爐全局參數(shù)優(yōu)化是離散的組合優(yōu)化問題,為此需采用離散粒子群優(yōu)化算法.
假設(shè)一個由m 個粒子組成的群體在D 維的搜索空間以一定的速度飛行,粒子i 在第t 次迭代中的狀態(tài)屬性設(shè)置如下: xi = ( xi1,xi2,…,xiD) ,xid∈[Ld,Ud]為第i 個粒子( i = 1,2,…,m,d = 1,2,…,D) 的維位置矢量,L d和Ud分別為搜索空間的下限和上限,根據(jù)適應(yīng)度函數(shù)計算xi當(dāng)前的適應(yīng)值,即可衡量粒子位置的優(yōu)劣; vi = ( vi1,vi2,…,viD) ,vid∈[vmin,vmax]為i 粒子的的飛行速度,即粒子移動的距離,v min和vmax分別為最小和最大速度; pi = ( pi1,pi2,…,piD) 為粒子自身迄今為止搜索到的最優(yōu)位置; pg = ( pg1,…,p gD) 為整個粒子群迄今為止搜索到的最優(yōu)位置. 對于離散組合優(yōu)化問題,粒子在每一個維度均被限定為0 或1,更新粒子的位置意味著改變某一位的狀態(tài)為0 或1,對于速度矢量,其相應(yīng)位表示的是xid取0 或1 的概率,在每次迭代中,粒子根據(jù)以下等式更新速度和位置:
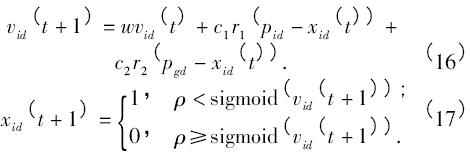
式中: t 是迭代次數(shù); r1、r2和ρ 為[0,1]之間的隨機(jī)數(shù),用于保持群體的多樣性; c1和c2為學(xué)習(xí)因子,使粒子具有自我總結(jié)和向群體中優(yōu)秀個體學(xué)習(xí)的能力,從而向自己的歷史最優(yōu)點(diǎn)以及群體內(nèi)歷史最優(yōu)點(diǎn)靠近,通常取c1 = c2 = 2; w 為慣性權(quán)重,其大小決定了粒子對當(dāng)前速度繼承的多少,選擇一個合適的w 有助于粒子群算法均衡它的探索能力與開發(fā)能力; sigmoid 數(shù)是常用的一種模糊函數(shù),其表達(dá)式為
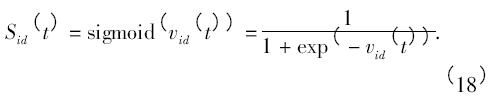
在離散粒子群優(yōu)化方法( discrete particle swarmoptimization,DSPO) 中,每個粒子平等的更新,忽視了最優(yōu)粒子的優(yōu)勢. 在現(xiàn)實世界中,大多數(shù)社會性動物都存在等級現(xiàn)象,最好的個體往往享受著某些特權(quán).因此根據(jù)粒子的表現(xiàn)好壞,應(yīng)采用不同的進(jìn)化策略.
首先,運(yùn)用式( 18) 計算概率向量,即probid = Sid .然后,根據(jù)如下原則更新粒子的概率向量,位置矢量和速度矢量: ( 1) 對于獲勝的粒子,根據(jù)式( 16) 和式( 17)分別更新其概率向量,位置矢量和速度矢量; ( 2) 對于失敗粒子,速度矢量和位置矢量按如下等式更新.
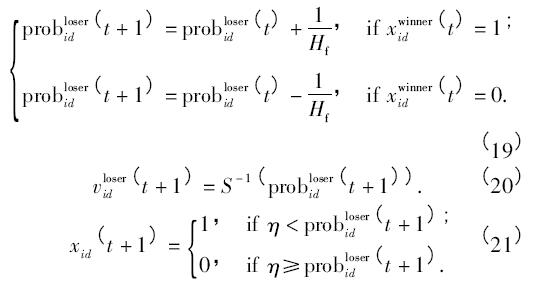
式中,Hf是層次因子,η 為[0,1]之間的隨機(jī)數(shù).
為了克服粒子過早成熟,在離散粒子群優(yōu)化方法中引入突變因素. 隨著迭代次數(shù)增加時,最優(yōu)的結(jié)果沒有得到改善,將執(zhí)行突變操作.
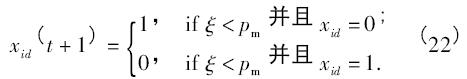
式中,pm是突變概率,ξ 是[0,1]之間的隨機(jī)數(shù).
2 高爐智能故障診斷模型
本文依據(jù)高爐冶煉原理和在長期生產(chǎn)實踐中積累的故障征兆描述,結(jié)合寶鋼2500 m3高爐自身先進(jìn)檢測技術(shù)的優(yōu)勢,對冶煉過程中出現(xiàn)的懸料、崩料和管道行程三種典型故障進(jìn)行診斷分析.
在進(jìn)行故障分析時,為了更好地反映真實的爐況狀態(tài),不能僅僅依賴高爐現(xiàn)場數(shù)據(jù)的瞬時值,而是要考慮一段時間內(nèi)數(shù)據(jù)的整體特征. 寶鋼現(xiàn)場數(shù)據(jù)采集系統(tǒng)采樣間隔為1 s,依據(jù)懸料、崩料和管道行程故障出現(xiàn)時在一段時間內(nèi)產(chǎn)生的異常現(xiàn)象,以900 個采樣點(diǎn)為周期,計算數(shù)據(jù)的均值、方差和變化率,最終確定爐況診斷系統(tǒng)的特征參數(shù)向量為F = ( GQ,CQ,HP,TP,ΔP,K) ,其中GQ 為煤氣流量,CQ 為冷風(fēng)流量,HP 為熱風(fēng)壓力,TP 為爐頂壓力,ΔP 為壓差,K 為透氣性指數(shù),各參數(shù)都由樣本均值、方差和變化率組成.
先進(jìn)的檢測技術(shù)為故障診斷帶來更多的信息支持,寶鋼2500 m3高爐在爐頂不同的位置安裝有六個微波雷達(dá),用于測量當(dāng)前料面上六個不同位置的料線深度,雷達(dá)數(shù)據(jù)能夠反映徑向料面和料速變化的規(guī)律.在爐喉斜橋方向開始沿圓周每隔90° 安裝一根測溫梁,其上共有17 個十字測溫點(diǎn),能自動連續(xù)地測出爐喉徑向溫度,根據(jù)溫度變化,能判斷煤氣流在爐喉的徑向分布. 在應(yīng)用改進(jìn)的均值濾波方法去除六點(diǎn)雷達(dá)數(shù)據(jù)的噪聲并采用二維滑動多項式曲面擬合對徑向的十字測溫數(shù)據(jù)進(jìn)行預(yù)處理[16],最終得到爐況診斷系統(tǒng)的環(huán)境信息向量為E = ( Rad1,Rad2,…,Rad6,CT,RT,ΔT) ,其中Radi,i=1,2,…,6 為六點(diǎn)雷達(dá)各自的波動值,CT 為中心點(diǎn)溫度均值,RT 為邊沿溫度均值,ΔT 為邊沿中心溫度差. 綜合上述參數(shù)集,形成最終的高爐診斷輸入向量IN = ( F,E) . 高爐智能故障診斷流程如圖3 所示.
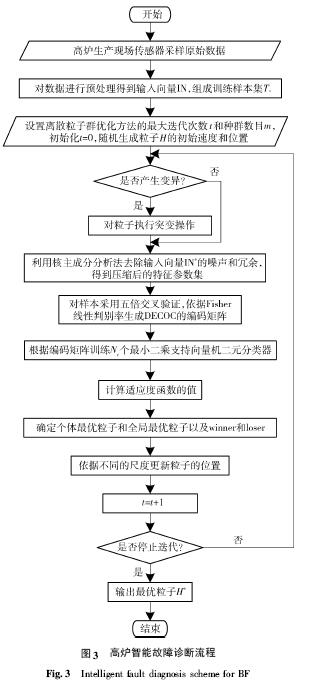
由于生產(chǎn)環(huán)境和檢測手段的限制,采樣數(shù)據(jù)往往變得極其復(fù)雜、混亂和冗余. 未經(jīng)預(yù)處理的采樣數(shù)據(jù)會導(dǎo)致所提取的特征參數(shù)受到不同程度的噪聲污染,從而影響診斷推理的精度. 由于特征參數(shù)選擇的隨意性且數(shù)量眾多,構(gòu)成樣本向量的不同特征參數(shù)之間常常具有一定的非線性相關(guān)性,大量的數(shù)據(jù)不但占用巨大的存儲空間和計算時間,加重了診斷推理機(jī)的負(fù)擔(dān),降低了系統(tǒng)的實時性,而且有用的知識往往會淹沒在大量的冗余數(shù)據(jù)中. 為了分析重要的特征,抑制無用的信息,需要進(jìn)行特征提取. 本文選用核主元分析法[17]對數(shù)據(jù)進(jìn)行壓縮和信息抽取,可以有效地找出數(shù)據(jù)中最主要的元素和結(jié)構(gòu),能夠消除特征參數(shù)間的冗余以及噪聲對特征參數(shù)的干擾,將原有的復(fù)雜數(shù)據(jù)降維,把眾多指標(biāo)轉(zhuǎn)化為少數(shù)幾個綜合指標(biāo),同時保留甚至強(qiáng)化了該數(shù)據(jù)的主要特征,揭示了隱藏在復(fù)雜數(shù)據(jù)背后的簡單結(jié)構(gòu),從而使數(shù)據(jù)更容易處理.
在整個診斷系統(tǒng)中,假設(shè)c = ( c1,c2,…,c n) 是n 個最小二乘支持向量機(jī)二元分類器的懲罰系數(shù),c i被限定在{ 20,21,…,210 } ; σ = ( σ1,σ2,…,σn,σKPCA) 是n +1 個徑向基核函數(shù)的寬度參數(shù),σi被限定在{ 2 - 3,2- 2,…,25 } ; f = { f1,f2,…,fm} 是m 個特征參數(shù)的特征選擇集,f i = 1 表示第i 個參數(shù)被選中,fi = 0 表示第i 個參數(shù)未被選中. 組合上述參數(shù)集,形成一個混合向量H= ( c,σ,f) ,需運(yùn)用變尺度離散粒子群優(yōu)化方法對其進(jìn)行優(yōu)化.
適應(yīng)度函數(shù)是系統(tǒng)總體表現(xiàn)的衡量標(biāo)準(zhǔn),根據(jù)系統(tǒng)的訓(xùn)練準(zhǔn)確率、支持向量的數(shù)量和參數(shù)選擇的個數(shù)評判每個粒子表現(xiàn)的優(yōu)劣. 現(xiàn)設(shè)定如下形式的適應(yīng)度函數(shù):
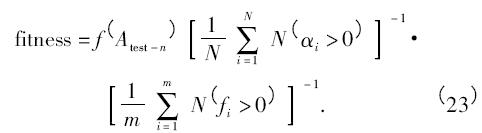
式中,f ( Atest - n) 表示對訓(xùn)練集的數(shù)據(jù)運(yùn)用n 重交叉檢驗的平均正確率,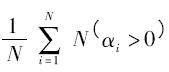 表示支持向量在所有訓(xùn)練樣本中占的比例,
表示支持向量在所有訓(xùn)練樣本中占的比例,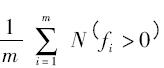 表示選中的特征參數(shù)在所有參數(shù)中占的比例.
表示選中的特征參數(shù)在所有參數(shù)中占的比例.
3 實驗仿真
為了檢驗本文提出的基于全局優(yōu)化支持向量機(jī)的多類別故障診斷方法,選取寶鋼高爐生產(chǎn)過程中具有代表性的500 組爐況數(shù)據(jù),其中正常爐況數(shù)據(jù)200 組,懸料、崩料和管道行程異常爐況各100 組,利用其中400 組數(shù)據(jù)作為訓(xùn)練樣本,剩余100 組作為測試樣本.
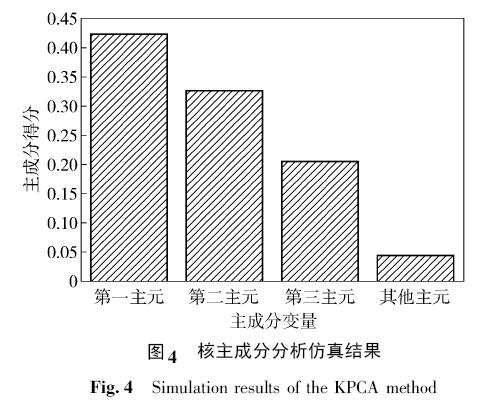
在故障檢測模型中,我們提取高爐特征數(shù)據(jù)IN =( F,E) . 該特征數(shù)據(jù)含有15 維特征,采用核主成分分析方法對其進(jìn)行降維處理. 圖4 展示了核主成分分析方法的仿真結(jié)果圖. 從圖中可以看到每個主元所代表數(shù)據(jù)特征的比重. 我們提取前三個主元所代表的特征數(shù)據(jù)作為模型的輸入. 前三個主元代表了95. 5%的特征屬性,能夠滿足模型的要求.
設(shè)置變尺度離散粒子群優(yōu)化方法最大迭代次數(shù)為300 次,最小二乘支持向量機(jī)分類器的懲罰因子c =( c1,c2,c3) 和徑向基核函數(shù)的寬度參數(shù)σ = ( σ1,σ2,σ3,σKPCA) 的自尋優(yōu)過程分別如圖5 和圖6 所示.
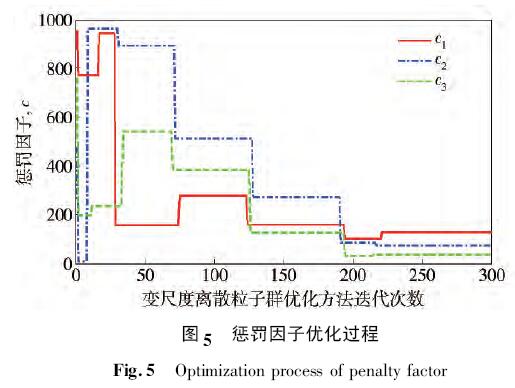
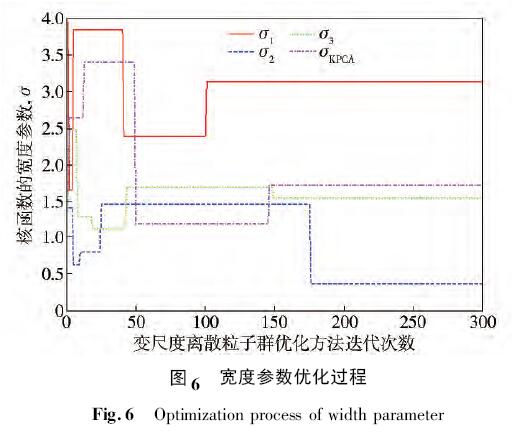
由圖5 和圖6 可以看出變尺度離散粒子群優(yōu)化方法在粒子尋優(yōu)的初期具有極大的搜索范圍,粒子的變異性能夠有效地防止粒子陷入局部極值,在搜索的后期,該算法能夠在小范圍內(nèi)對最優(yōu)值進(jìn)行調(diào)整,最終得到的最優(yōu)參數(shù)如表3 所示.
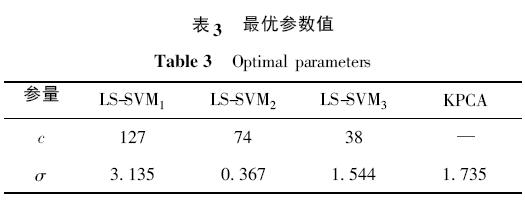
進(jìn)一步,對高爐故障訓(xùn)練樣本采用Fisher 線性判別糾錯輸出編碼法得到編碼矩陣,如表4 所示.
在測試階段,本文將基于參數(shù)優(yōu)化的糾錯輸出編碼多類別故障診斷方法與傳統(tǒng)的無參數(shù)優(yōu)化( c = 10,σ = 0. 4) 的一對一、一對多、密集隨機(jī)編碼和稀疏隨機(jī)編碼四種方法進(jìn)行對比,進(jìn)行1000 次實驗后得到平均結(jié)果如表5 所示.
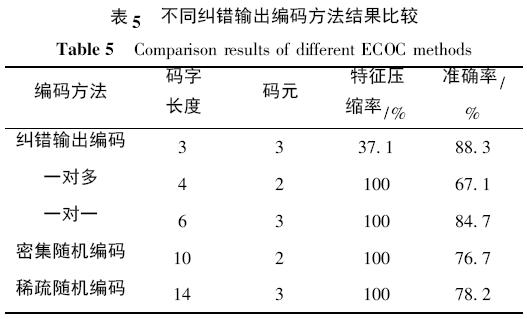
由表5 可以看出故障樣本經(jīng)過特征參數(shù)的篩選和壓縮之后,顯著降低了樣本的維數(shù)且提高了樣本的質(zhì)量,減輕了最小二乘支持向量機(jī)分類器的運(yùn)算負(fù)擔(dān),增強(qiáng)了系統(tǒng)的分類性能. 與其他四種方法相比糾錯輸出編碼方法提供了最為緊湊的編碼,碼字長度代表著采用最小二乘支持向量機(jī)分類器的個數(shù). 通過表5 可以看出,通過糾錯輸出編碼后,我們采用三個最小二乘支持向量機(jī)的分類器就可以實現(xiàn)高爐故障的識別. 相比于其他算法,分類器的個數(shù)得到了很好的抑制,降低了故障識別時間. 利用Fisher 判別率對類集合的重新整合,幫助分類器得到了較高的準(zhǔn)確率. 就系統(tǒng)的復(fù)雜性而言,一對多方法與糾錯輸出編碼法最為接近,但是前者的準(zhǔn)確率卻是較低的,因為這種方法容易受到不同類別訓(xùn)練樣本數(shù)量不均衡的影響. 雖然隨機(jī)編碼方法也得到了可以接受的效果. 但是,由于它們需要構(gòu)造的分類器數(shù)量過多,嚴(yán)重影響了系統(tǒng)的實時性,不利于高爐生產(chǎn)現(xiàn)場爐況的在線監(jiān)測. 相比而言,一對一方法得到了與糾錯輸出編碼相近的分類結(jié)果,并且其編碼構(gòu)造方式固定,構(gòu)造過程簡單,可以作為一種備用的高爐故障診斷系統(tǒng)的編碼選擇.
4 結(jié)論
本文針對特定高爐選取與典型故障密切相關(guān)的特征統(tǒng)計參數(shù),從數(shù)據(jù)預(yù)處理和參數(shù)優(yōu)化兩個方面著手,應(yīng)用變尺度離散粒子群優(yōu)化方法提升了最小二乘支持向量機(jī)二元分類器的整體性能,進(jìn)而通過啟發(fā)式的糾錯輸出編碼設(shè)計,將二元分類器推廣至多元故障分類,使用較少的分類器,在提升系統(tǒng)實時性的同時得到了良好的診斷效果,為高爐故障的在線監(jiān)控提出了一種可行的方法.
參 考 文 獻(xiàn)
[1] Liang J B. The Blast Furnace Condition Diagnosis System Designand Implementation based on the Gas Flow Rate [Dissertation].Changsha: Central South University,2009
( 梁劍波. 基于煤氣流量的高爐爐況診斷系統(tǒng)設(shè)計及實現(xiàn)[學(xué)位論文]. 長沙: 中南大學(xué),2009)
[2] Li Q H. Fuzzy Identification Prediction and Control to B. F IronmakingProcess [Dissertation]. Zhejiang: Zhejiang University,2005
( 李啟會. 高爐冶煉過程的模糊辨識、預(yù)測與控制[學(xué)位論文]. 浙江: 浙江大學(xué),2005)
[3] Gao C H,Jian L,Chen J M,et al. Data-driven modeling andpredictive algorithm for complex blast furnace ironmaking process.Acta Autom Sin,2009,35( 6) : 725
( 郜傳厚,漸令,陳積明,等. 復(fù)雜高爐煉鐵過程的數(shù)據(jù)驅(qū)動建模及預(yù)測算法. 自動化學(xué)報,2009,35( 6) : 725)
[4] Liu L M,Wang A N,Sha M,et al. Fault diagnostics of blast furnacebased on CLS--SVM / / 2010 Chinese Conference on PatternRecognition. IEEE,2010
[5] Yang J,Xu Q,Yu C B,et. al. Study on fault diagnosis of blastfurnace based on ICA--QNN / / Proceedings of the 29th ChineseControl Conference. Beijing,2010: 4014
( 楊佳,許強(qiáng),余成波,等. 基于ICA--QNN 的高爐故障診斷研究/ / 第29 屆中國控制會議. 北京,2010: 4014)
[6] Li Z. Research of Blast Furnace Fault Diagnosis based on BayesianNetworks [Dissertation]. Wuhan: Wuhan University of Scienceand Technology,2015
( 李振. 基于貝葉斯網(wǎng)絡(luò)( Bayesian Networks) 方法的高爐故障診斷研究[學(xué)位論文]. 武漢: 武漢科技大學(xué),2015)
[7] Pujol O,Radeva P,Vitria J. Discriminant ECOC: a heuristicmethod for application dependent design of error correcting outputcodes. IEEE Trans Pattern Anal Mach Intell,2006,28( 6) : 1007
[8] Suykens J A K,Vandewalle J. Least squares support vector machineclassifiers. Neural Process Lett,1999,9( 3) : 293
[9] Xu M,Wang S T,Gu X. TL--SVM: A transfer learning algorithm.Control Decis,2014,29( 1) : 141
( 許敏,王士同,顧鑫. TL--SVM: 一種遷移學(xué)習(xí)新算法. 控制與決策,2014,29( 1) : 141)
[10] Gestel T V,Suykens J A K,Lanckriet G,et al. Multiclass LS--SVMs: moderated outputs and coding-decoding schemes. NeuralProcess Lett,2002,15( 1) : 45
[11] Liu L M,Wang A N,Sha M,et. al. Multi-class classificationmethods of cost-conscious LS--SVM for fault diagnosis of blastfurnace. J Iron Steel Res Int,2011,18( 10) : 17
[12] Qiu M H,Wang Z Y,An G,et al. Diagnosis of gear fault basedon KPCA and ECOC--SVM. J Vib Shock,2009,28( 5) : 1
( 邱綿浩,王自營,安鋼,等. 基于核主元分析與糾錯輸出編碼SVM 的齒輪故障診斷. 振動與沖擊,2009,28( 5) : 1)
[13] Allwein E,Schapire R,Singer Y. Reducing multiclass to binary:a unifying approach for margin classifiers. Mach Learn Res,2002,12( 1) : 113
[14] Zhou J D,Wang X D,Cui Y H,et al. Error-correcting outputcodes based on evidence theory for multi-class classification.Control Decis,2013,28( 4) : 495
( 周進(jìn)登,王曉丹,崔永花,等. 基于證據(jù)理論的糾錯輸出編碼解決多類分類問題. 控制與決策,2013,28( 4) : 495)
[15] Ji Z,Liao H L,Wu Q H. Particle Swarm Optimization Algorithmand Its Application. Beijing: Science Press,2009
( 紀(jì)震,廖惠連,吳青華. 粒子群算法及應(yīng)用. 1 版. 北京:科學(xué)出版社,2009)
[16] Hao Y. Study on Radar and Cross Temperature Data Processingin Blast Furnace [Dissertation]. Beijing: University of Scienceand Technology Beijing,2012
( 郝宇. 高爐雷達(dá)及十字測溫數(shù)據(jù)處理算法研究[學(xué)位論文]. 北京: 北京科技大學(xué),2012)
[17] Cao L J,Chua K S,Chong W K,et al. A comparison of PCA,KPCA and ICA for dimensionality reduction in support vector machine.Neurocomputing,2003,55( 1-2) : 321